

 Home
Home
Supervised and Sponsored by Chongqing Southwest Information Co., Ltd.
CODEN JKIEBK


 Current Issue
Current Issue

-
Advances in End-to-End Optimized Image Compression Technologies
刘东, 王叶斐, 林建平, 马海川, 杨闰宇. 端到端优化的图像压缩技术进展[J]. 计算机科学, 2021, 48(3): 1-8.
LIU Dong, WANG Ye-fei, LIN Jian-ping, MA Hai-chuan, YANG Run-yu. Advances in End-to-End Optimized Image Compression Technologies[J]. Computer Science, 2021, 48(3): 1-8. - LIU Dong, WANG Ye-fei, LIN Jian-ping, MA Hai-chuan, YANG Run-yu
- Computer Science. 2021, 48 (3): 1-8. doi:10.11896/jsjkx.201100134
-
 Abstract
Abstract
 PDF(2746KB) (
4236
)
PDF(2746KB) (
4236
)
- References | Related Articles | Metrics
-
Image compression is the application of data compression technologies on digital images,aiming to reduce redundancy in image data,so as to store and transmit data with a more efficient format.In traditional image compression methods,image compression is divided into several steps,such as prediction,transform,quantization and entropy coding,and each step is optimized by manually designed algorithm separately.In recent years,end-to-end image compression methods based on deep neural networks have achieved fruitful results.Compared with the traditional methods,end-to-end image compression can be optimized jointly,which often achieves higher compression efficiency than the traditional methods.In this paper,the end-to-end image compression methods and network structures are introduced,and the key technologies of end-to-end image compression are described,including quantization technology,probability modeling and entropy coding technology,as well as encoder-side bit allocation technology.Then it introduces the research of extended applications of end-to-end image compression,including scalable coding,variable bit rate compression,visual perception and machine perception oriented compression.Finally,the compression efficiency of end-to-end image compression is compared with the traditional methods,and the compression performance is demonstrated.Experimental results show that the compression efficiency of the state-of-the-art end-to-end image compression method is much higher than that of the traditional image coding methods including JPEG,JPEG2000 and HEVC intra.Compared with the newest coding standard VVC intra,the end-to-end image compression method can save up to 48.40% of the coding rate while maintain the same MS-SSIM.
-
Research Progress on Deep Learning-based Image Deblurring
潘金山. 基于深度学习的图像去模糊方法研究进展[J]. 计算机科学, 2021, 48(3): 9-13.
PAN Jin-shan. Research Progress on Deep Learning-based Image Deblurring[J]. Computer Science, 2021, 48(3): 9-13. - PAN Jin-shan
- Computer Science. 2021, 48 (3): 9-13. doi:10.11896/jsjkx.201200043
-
Abstract
PDF(1258KB) (
4560
)
- References | Related Articles | Metrics
-
With the increasing development of portable and smart digital imaging devices,the way to capture photos is more convenient and flexible.Digital images play an important role in video surveillance,medical diagnosis,space exploration,and so on.However,the captured images usually contain significant blur and noise due to the limited quality of the camera sensors,the skill of the photographers,and the imaging environments.How to restore the clear images from blurry ones so that they can facilitate the following intelligent analysis tasks is important but challenging.Image deburring is a classical ill-posed problem.Represented methods for this problem include the statistical prior-based methods and data-driven methods.However,conventional statistical prior-based methods have limited ability for modeling the inherent properties of the clear images.The data-driven methods,especially the deep learning methods,provide an effective way to solve image deblurring.This paper focuses on the deep learning-based image deblurring methods.It first introduces the research progress of the image deblurring problem,and then analyzes the challenges of the image deblurring problem.Finally,it discusses the research trends of the image deblurring problem.
-
Survey on Image Inpainting Research Progress
赵露露, 沈玲, 洪日昌. 图像修复研究进展综述[J]. 计算机科学, 2021, 48(3): 14-26.
ZHAO Lu-lu, SHEN Ling, HONG Ri-chang. Survey on Image Inpainting Research Progress[J]. Computer Science, 2021, 48(3): 14-26. - ZHAO Lu-lu, SHEN Ling, HONG Ri-chang
- Computer Science. 2021, 48 (3): 14-26. doi:10.11896/jsjkx.210100048
-
Abstract
PDF(2724KB) (
6748
)
- References | Related Articles | Metrics
-
Image inpainting is a challenging research topic in the field of computer vision.In recent years,the development of deep learning technology has promoted the significant improvement in the performance of image inpainting,which makes image inpainting a traditional subject attracting extensive attention from scholars once again.This paper is dedicated to review the key technologies of image inpainting research.Due to the important role and far-reaching impact of deep learning technology in solving “large-area missing image inpainting”,this paper briefly introduces traditional image inpainting methods firstly,then focuses on inpainting models based on deep learning,mainly including model classification,comparison of advantages and disadvantages,scope of application and performance comparison on commonly used datasets,etc.Finally,the potential research directions and development trends of image inpainting are analyzed and prospected.
-
Adversarial Attacks and Defenses on Multimedia Models:A Survey
陈凯, 魏志鹏, 陈静静, 姜育刚. 多媒体模型对抗攻防综述[J]. 计算机科学, 2021, 48(3): 27-39.
CHEN Kai, WEI Zhi-peng, CHEN Jing-jing, JIANG Yu-gang. Adversarial Attacks and Defenses on Multimedia Models:A Survey[J]. Computer Science, 2021, 48(3): 27-39. - CHEN Kai, WEI Zhi-peng, CHEN Jing-jing, JIANG Yu-gang
- Computer Science. 2021, 48 (3): 27-39. doi:10.11896/jsjkx.210100079
-
Abstract
PDF(1638KB) (
2650
)
- References | Related Articles | Metrics
-
In recent years,with the rapid development and wide application of deep learning,artificial intelligence is profoundly changing all aspects of social life.However,artificial intelligence models are also vulnerable to well-designed “adversarial examples”.By adding subtle perturbations that are imperceptible to humans on clean image or video samples,it is possible to generate adversarial examples that can deceive the model,which leads the multimedia model to make wrong decisions in the inference process,and bring serious security threat to the actual application and deployment of the multimedia model.In view of this,adversarial examples generation and defense methods for multimedia models have attracted widespread attention from both academic and industry.This paper first introduces the basic principles and relevant background knowledge of adversarial examples generation and defense.Then,it reviews the recent progress on both adversarial attack and defense on multimedia models.Finally,it summarizes the current challenges as well as the future directions for adversarial attacks and defenses.
-
Advances on Visual Object Tracking in Past Decade
张开华, 樊佳庆, 刘青山. 视觉目标跟踪十年研究进展[J]. 计算机科学, 2021, 48(3): 40-49.
ZHANG Kai-hua, FAN Jia-qing, LIU Qing-shan. Advances on Visual Object Tracking in Past Decade[J]. Computer Science, 2021, 48(3): 40-49. - ZHANG Kai-hua, FAN Jia-qing, LIU Qing-shan
- Computer Science. 2021, 48 (3): 40-49. doi:10.11896/jsjkx.201100186
-
Abstract
PDF(2602KB) (
2773
)
- References | Related Articles | Metrics
-
Visual object tracking is a task in which the target region of the first frame in a video sequence is given,and then the target area is automatically matched in subsequent frames.Generally speaking,due to the complex factors such as scene occlusion,illumination change and object deformation,the appearance of the target and scene will change dramatically,which makes the tracking task itself is extremely challenging.In the past decade,with the extensive application of deep learning in the field of computer vision,the field of target tracking has also developed rapidly,resulting in a series of excellent algorithms.In view of this rapid development stage,this paper aims to provide a comprehensive review of visual object tracking research,mainly including the following aspects:the improvement of the basic framework of tracking,the improvement of target representation,the improvement of spatial context,the improvement of temporal context,the improvement of data sets and evaluation indicators.This paper also analyzes the advantages and disadvantages of these methods,and puts forward the possible future research trends.
-
Survey on Video-based Face Recognition
白子轶, 毛懿荣, 王瑞平. 视频人脸识别进展综述[J]. 计算机科学, 2021, 48(3): 50-59.
BAI Zi-yi, MAO Yi-rong , WANG Rui-ping. Survey on Video-based Face Recognition[J]. Computer Science, 2021, 48(3): 50-59. - BAI Zi-yi, MAO Yi-rong , WANG Rui-ping
- Computer Science. 2021, 48 (3): 50-59. doi:10.11896/jsjkx.210100210
-
Abstract
PDF(2916KB) (
2835
)
- References | Related Articles | Metrics
-
Face recognition is a key technology in the field of biometrics,which has been widely concerned by researchers in the past decades.Video-based face recognition task refers specifically to extract the key information of human faces from a video to complete the personal identification.Compared with the image-based face recognition task,the changing patterns of faces in videos are much more diverse,and there are great differences among the whole video frames as well.Current research focuses on how to extract the key features of faces from lengthy videos.Firstly,this paper introduces the research value and challenges of video-based face recognition.Then,the developing venation of the current research work is explored.Based on the video modeling manners,traditional image set based methods are divided into four categories:linear subspace modeling,affine subspace modeling,nonlinear manifold modeling and statistical modeling.Besides,the methods based on image fusion under the background of deep learning are also introduced.This paper also briefly reviews existing datasets for video-based face recognition and the commonly used performance metrics.Finally,gray features and deep features are used to evaluate the representative works on YTC dataset and IJB-A dataset.Experimental results show that deep neural network can extract robust features of each frame after being trained with large-scale data,which greatly improves the performance of video-based face recognition.Moreover,the effective vi-deo modeling can help to identify the potential human face changing patterns.Therefore,more discriminative information can be found from the large number of samples contained in the video sequence,and the inference of noise samples can be eliminated,which suggests the advantages of video-based face recognition to be applied to a large range of practical application scenarios.
-
Review of Sign Language Recognition, Translation and Generation
郭丹, 唐申庚, 洪日昌, 汪萌. 手语识别、翻译与生成综述[J]. 计算机科学, 2021, 48(3): 60-70.
GUO Dan, TANG Shen-geng, HONG Ri-chang, WANG Meng. Review of Sign Language Recognition, Translation and Generation[J]. Computer Science, 2021, 48(3): 60-70. - GUO Dan, TANG Shen-geng, HONG Ri-chang, WANG Meng
- Computer Science. 2021, 48 (3): 60-70. doi:10.11896/jsjkx.210100227
-
Abstract
PDF(2250KB) (
4832
)
- References | Related Articles | Metrics
-
Sign language research is a typical cross-disciplinary research topic,involving computer vision,natural language processing,cross-media computing and human-computer interaction.Sign language research mainly includes isolated sign language recognition,continuous sign language translation and sign language video generation.Sign language recognition and translation aim to convert sign language videos into textual words or sentences,while sign language generation synthesizes sign videos based on spoken or textual sentences.In other words,sign language translation and generation are inverse processes.This paper reviews the latest progress of sign language research,introduces its background and challenges,reviews typical methods and cutting-edge research on sign language recognition,translation and generation tasks.Combining with the problems in the current methods,the future research direction of hand language is prospected.
-
Survey of Cross-media Question Answering and Reasoning Based on Vision and Language
武阿明, 姜品, 韩亚洪. 基于视觉和语言的跨媒体问答与推理研究综述[J]. 计算机科学, 2021, 48(3): 71-78.
WU A-ming, JIANG Pin, HAN Ya-hong. Survey of Cross-media Question Answering and Reasoning Based on Vision and Language[J]. Computer Science, 2021, 48(3): 71-78. - WU A-ming, JIANG Pin, HAN Ya-hong
- Computer Science. 2021, 48 (3): 71-78. doi:10.11896/jsjkx.201100176
-
Abstract
PDF(1726KB) (
2329
)
- References | Related Articles | Metrics
-
Cross-media question answering and reasoning based on vision and language is one of the popular research hotspots of artificial intelligence.It aims to return a correct answer based on understanding of the given visual content and related questions.With the rapid development of deep learning and its wide application in computer vision and natural language processing,cross-media question answering and reasoning based on vision and language has also achieved rapid development.This paper systematically surveys the current researches on cross-media question answering and reasoning based on vision and language,and specifi-cally introduces the research progress of image-based visual question answe-ring and reasoning,video-based visual question answering and reasoning,and visual commonsense reasoning.Particularly,image-based visual question answering and reasoning is subdivided into three categories,i.e.,multi-modal fusion,attention mechanism,and reasoning based methods.Meanwhile,visual commonsense reasoning is subdivided into reasoning and pre-training based methods.Moreover,this paper summarizes the commonly used datasets of question answering and reasoning,as well as the experimental results of representative methods.Finally,this paper looks forward to the future development direction of cross-media question answering and reasoning based on vision and language.
-
Overview of Research on Cross-media Analysis and Reasoning Technology
王树徽, 闫旭, 黄庆明. 跨媒体分析与推理技术研究综述[J]. 计算机科学, 2021, 48(3): 79-86.
WANG Shu-hui, YAN Xu, HUANG Qing-ming. Overview of Research on Cross-media Analysis and Reasoning Technology[J]. Computer Science, 2021, 48(3): 79-86. - WANG Shu-hui, YAN Xu, HUANG Qing-ming
- Computer Science. 2021, 48 (3): 79-86. doi:10.11896/jsjkx.210200086
-
Abstract
PDF(2405KB) (
4363
)
- References | Related Articles | Metrics
-
Cross-media presents complex correlation characteristics across modalities and data sources.Cross-media analysis and reasoning technology is aimed at multimodal information understanding and interaction tasks.Through the construction of cross-modal and cross-platform semantic transformation mechanisms,as well as further question-and-answer interactions,it is constantly approaching complex cognitive goals and modeling high-level cross the logical reasoning process of modal information,finally multimodal artificial intelligence is realized.This paper summarizes the research background and development history of cross-media analysis and reasoning technology,and summarizes the key technologies of cross-modal tasks involving vision and language.Based on the existing research,this paper analyzes the existing problems in the field of multimedia analysis,and finally discusses the future development trend.
-
Survey on Visual Question Answering and Dialogue
牛玉磊, 张含望. 视觉问答与对话综述[J]. 计算机科学, 2021, 48(3): 87-96.
NIU Yu-lei, ZHANG Han-wang. Survey on Visual Question Answering and Dialogue[J]. Computer Science, 2021, 48(3): 87-96. - NIU Yu-lei, ZHANG Han-wang
- Computer Science. 2021, 48 (3): 87-96. doi:10.11896/jsjkx.201200174
-
Abstract
PDF(1426KB) (
3107
)
- References | Related Articles | Metrics
-
Visual question answering and dialogue are important research tasks in artificial intelligence,and the representative problems in the intersection of computer vision and natural language processing.Visual question answering and dialogue tasks require the machine to answer single-round or multi-round questions based on the specified visual content.Visual question answering and dialogue require the machine’s abilities of perception,cognition and reasoning,and have application prospects in cross-modal human-computer interaction applications.This paper reviews recent research progress of visual question answering and dialogue,and summarizes datasets,algorithms,challenges,and problems.Finally,this paper discusses the future research trend of visual question answering and dialogue.
-
Survey of Multimedia Social Events Analysis
钱胜胜, 张天柱, 徐常胜. 多媒体社会事件分析综述[J]. 计算机科学, 2021, 48(3): 97-112.
QIAN Sheng-sheng, ZHANG Tian-zhu, XU Chang-sheng. Survey of Multimedia Social Events Analysis[J]. Computer Science, 2021, 48(3): 97-112. - QIAN Sheng-sheng, ZHANG Tian-zhu, XU Chang-sheng
- Computer Science. 2021, 48 (3): 97-112. doi:10.11896/jsjkx.210200023
-
Abstract
PDF(3323KB) (
2213
)
- References | Related Articles | Metrics
-
With the rapid development of network technology,various Internet-based communication channels,such as self-media,Weibo,BBS,are becoming perfect platforms for people to easily generate and share rich social multimedia content online.Social event data have the characteristics of multi-platform,multi-modal,large-scale and high noise,which bring huge challenges for the analysis and research based on multimedia social events.Therefore,how to process social media data,study social event analysis methods,and design effective social event analysis models become key issues in social event analysis research.This paper presents a review of relevant research in multimedia social event analysis in recent years,focusing on multimedia social event representation methods and their applications in the fields of fake news detection,multimedia hot event detection,tracking and evolution analysis,as well as social media crisis event response.In addition,the datasets involved in different applications are introduced in detail.In the last section,this paper discusses possible future research topics in multimedia social event analysis.
-
Hybrid Score Function for Collaborative Filtering Recommendation
肖诗涛, 邵蓥侠, 宋卫平, 崔斌. 面向协同过滤推荐的新型混合评分函数[J]. 计算机科学, 2021, 48(3): 113-118.
XIAO Shi-tao, SHAO Ying-xia, SONG Wei-ping, CUI Bin. Hybrid Score Function for Collaborative Filtering Recommendation[J]. Computer Science, 2021, 48(3): 113-118. - XIAO Shi-tao, SHAO Ying-xia, SONG Wei-ping, CUI Bin
- Computer Science. 2021, 48 (3): 113-118. doi:10.11896/jsjkx.200900067
-
Abstract
PDF(2279KB) (
1493
)
- References | Related Articles | Metrics
-
Collaborative Filtering has been widely used in modern recommendation systems,and it assumes that similar users prefer similar items.A key ingredient of CF-based recommendation model is the score function,which measures the preference of users on items.However,there are some shortages in the most popular score functions.The inner product score function fails to capture the user-user similarity and item-item similarity effectively,and Euclidean distance measurement function reduces the expressiveness of the model because of its geometrical restriction.This paper proposes a novel hybrid score function by mixing the inner product-based similarity and the Euclidean distance metric,and further theoretically analyze its properties,thus proving that the new score function can avoid the aforementioned shortages effectively.In addition,the new hybrid score function is a general technique and can help to improve the quality of recommendation for existing models (e.g.,SVD++,MF,NGCF,CML).Extensive empirical studies over 6 datasets demonstrate the superior performance of the proposed hybrid score function.
-
Web-based Data Visualization Chart Rendering Optimization Method
鄂海红, 张田宇, 宋美娜. 基于Web的数据可视化图表渲染优化方法[J]. 计算机科学, 2021, 48(3): 119-123.
E Hai-hong, ZHANG Tian-yu, SONG Mei-na. Web-based Data Visualization Chart Rendering Optimization Method[J]. Computer Science, 2021, 48(3): 119-123. - E Hai-hong, ZHANG Tian-yu, SONG Mei-na
- Computer Science. 2021, 48 (3): 119-123. doi:10.11896/jsjkx.200600038
-
Abstract
PDF(1943KB) (
2137
)
- References | Related Articles | Metrics
-
In data visualization scenario,as load-bearing body of data visualization,the web page’s performance directly affects the loading speed and rendering effect of the visualization chart.At present,the optimization method based on web technology cannot reduce the pressure of network data transmission caused by charts obtaining large-scale complex data for rendering and redra-wing.In view of the above problems,a web-based data visualization chart rendering method is proposed.Firstly,it combines the caching mechanism and the incremental update algorithm,and deeply optimizes the HTTP request response body from the aspects of chart style and its interactive configuration information and chart binding data.Then,by reducing the size of the HTTP request response body,it reduces the amount of network data transmission and shortens the download time of data resources by reducing the size of the HTTP request response body,thereby improving the chart loading speed and shortening the page rendering time.Finally,a full comparison experiment is carried out for this method.Experimental results show that the total HTTP response time of a single chart is shortened from 75 ms to 28 ms,and the total rendering time of multiple charts displayed on web pages is shortened from 1546 ms to 1 337 ms,thus the effectiveness of this method is verified.
-
Smooth Representation-based Semi-supervised Classification
王省, 康昭. 基于光滑表示的半监督分类算法[J]. 计算机科学, 2021, 48(3): 124-129.
WANG Xing , KANG Zhao. Smooth Representation-based Semi-supervised Classification[J]. Computer Science, 2021, 48(3): 124-129. - WANG Xing , KANG Zhao
- Computer Science. 2021, 48 (3): 124-129. doi:10.11896/jsjkx.200700078
-
Abstract
PDF(2389KB) (
1435
)
- References | Related Articles | Metrics
-
Graph-based semi-supervised classification is a hot topic in machine learning and data mining.In general,this method discovers the hidden information by constructing a graph and predicts the labels for unlabeled samples based on the structural information of graph.Thus,the performance of semi-supervised classification heavily depends on the quality of graph.In this work,we propose to perform semi-supervised classification in a smooth representation.In particular,a low-pass filter is applied on the data to achieve a smooth representation,which in turn is used for semi-supervised classification.Furthermore,a unified framework which integrates graph construction and label propagation is proposed,so that they can be mutually improved and avoid the sub-optimal solution caused by low-quality graph.Extensive experiments on face and subject data sets show that the proposed SRSSC outperforms other state-of-the-art methods in most cases,which validates the significance of smooth representation.
-
NVRC:Write-limited Logging for Non-volatile Memory
范鹏浩, 黄国锐, 金培权. NVRC:一种面向NVM的写限制日志方案[J]. 计算机科学, 2021, 48(3): 130-135.
FAN Peng-hao, HUANG Guo-rui, JIN Pei-quan. NVRC:Write-limited Logging for Non-volatile Memory[J]. Computer Science, 2021, 48(3): 130-135. - FAN Peng-hao, HUANG Guo-rui, JIN Pei-quan
- Computer Science. 2021, 48 (3): 130-135. doi:10.11896/jsjkx.200900071
-
Abstract
PDF(1557KB) (
1311
)
- References | Related Articles | Metrics
-
Non-volatile memory (NVM) has the characteristics of byte addressing,persistence,high storage density,low read-write delay,etc.,so it becomes the preferred technology to solve the problem of limited DRAM(Dynamic Random Access Memory) capacity.With the introduction of NVM in database systems,traditional log technologies need to consider how to adapt to the characteristics of NVM.This paper first summarizes the existing research on NVM oriented log technologies,and then proposes a database log scheme called NVRC(Non-Volatile Record-updating with Cacheline) that limits NVM write operations as much as possible.This paper puts forward a log management scheme which combines out-place and in-place update.Specifically,on the basis of out-place-update-based shadow records,NVRC introduces the strategy of “in-place cache line update”,and dynamically selects the log update strategy through cost analysis,so as to reduce the writes to NVM.This paper uses DRAM to simulate NVM to experiment on the YCSB benchmark,and compares NVRC with the traditional WAL(Write Ahead Log) and the NVM-oriented logging scheme PCMLx(PCMLoggingx).The results show that the number of NVM writes of NVRC is 54% and 17% less than that of WAL and PCMLx respectively,and the update performance improves by 59% and 10% respectively.
-
Measure for Multi-fractals of Weighted Graphs
刘胜久, 李天瑞, 谢鹏, 刘佳. 带权图的多重分形度量[J]. 计算机科学, 2021, 48(3): 136-143.
LIU Sheng-jiu, LI Tian-rui, XIE Peng, LIU Jia. Measure for Multi-fractals of Weighted Graphs[J]. Computer Science, 2021, 48(3): 136-143. - LIU Sheng-jiu, LI Tian-rui, XIE Peng, LIU Jia
- Computer Science. 2021, 48 (3): 136-143. doi:10.11896/jsjkx.200700159
-
Abstract
PDF(1425KB) (
1242
)
- References | Related Articles | Metrics
-
Fractal dimension and multi-fractal are important research contents of fractal theory.The multi-fractal of complex networks has been studied in depth,while there is no feasible method to measure the multi-fractal of complex networks.Weighted graph is an important research object of complex network.Both node weight and edge weight in weighted graphs can be positive real number,negative real number,pure imaginary number and complex number,and so on.Among all types of weighted graphs,except the weighted graphs with both node weight and edge weight being positive real numbers,other types of weighted graphs share multi-fractals and append with infinity complex network dimensions.Through the study of multi-fractals of weighted graphs,this paper presents modulus of infinity complex network dimensions of all 15 weighted graphs that share multi-fractal,and measures multi-fractal of them by cardinality of sets obtained from modulus of infinity complex network dimensions of them.It shows that all sets obtained from modulus of infinity complex network dimensions of weighted graphs share multi-fractal are countable sets,while 2 are multisets,and the other 13 are ordinary sets.Moreover,all sets,regardless of multisets or ordinary sets,are equipotent with cardinality of
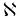 0.
0.
-
Mechanism Design of Right to Earnings of Data Utilization Based on Evolutionary Game Model
商希雪, 韩海庭, 朱郑州. 基于演化博弈的数据收益权分配机制设计[J]. 计算机科学, 2021, 48(3): 144-150.
SHANG Xi-xue, HAN Hai-ting, ZHU Zheng-zhou. Mechanism Design of Right to Earnings of Data Utilization Based on Evolutionary Game Model[J]. Computer Science, 2021, 48(3): 144-150. - SHANG Xi-xue, HAN Hai-ting, ZHU Zheng-zhou
- Computer Science. 2021, 48 (3): 144-150. doi:10.11896/jsjkx.201100056
-
Abstract
PDF(2195KB) (
1713
)
- References | Related Articles | Metrics
-
In order to solve the problemsin the process of marketization of data elements,such as the difficulty of complete deli-very of data,the difficulty of fair division of data property rights,and thesuperiority of enterprises in the game between indivi-duals and enterprises,this paper proposes the concept of data utilization to get rid of the restriction of traditional property rights concept,andmakes the trading system better adapt to the general characteristics ofthe data market.At the same time,the evolutionary game analysis of economics is used to transform the direct distribution of data revenue into rational individual and enterprise mutual trial and error,and to explore the group advantage strategies that tend to converge under different conditions,so as to realize the fairness of distribution and the “Kaldor-Hicks efficiency”.Finally,the weight formula of the proportionality principle injustice is introduced to make the judicial trial computable,programmable and controllable.Algorithm analysis and si-mulation experiments prove that the game framework can well realize market equilibrium under realistic conditions,and find the convergence characteristics and convergence speeds under different Wij conditions,providing an important quantitative analysis tool for judicial practice.
-
Density Peaks Clustering Algorithm Based on Natural Nearest Neighbor
汤鑫瑶, 张正军, 储杰, 严涛. 基于自然最近邻的密度峰值聚类算法[J]. 计算机科学, 2021, 48(3): 151-157.
TANG Xin-yao, ZHANG Zheng-jun, CHU Jie, YAN Tao. Density Peaks Clustering Algorithm Based on Natural Nearest Neighbor[J]. Computer Science, 2021, 48(3): 151-157. - TANG Xin-yao, ZHANG Zheng-jun, CHU Jie, YAN Tao
- Computer Science. 2021, 48 (3): 151-157. doi:10.11896/jsjkx.200100112
-
Abstract
PDF(2581KB) (
1551
)
- References | Related Articles | Metrics
-
Aiming at the problem that the density peak clustering (DPC) algorithm requires manually selected parameters (cutoff distance dc),as well as the problem of a poor performance on complex data sets caused by the simple definition of local density and the one-step assignment strategy,a new density peak clustering algorithm based on natural nearest neighbors (NNN-DPC) is proposed.The algorithm does not need to specify any parameters and is a non-parametric clustering method.Based on the definition of natural nearest neighbors,this algorithm firstly gives a new local density calculation formula to describe the distribution of data,and reveals the internal connection.A two-step assignment strategy is designed to divide the sample points.Finally,the similarity between clusters is defined,and a new cluster merging rule is proposed to merge the clusters to obtain the final clustering result.The experimental results show that without parameters,the NNN-DPC algorithm has excellent generalization ability on various types of data sets,and can more accurately identify the number and distribution of clusters on manifold data or data with large differences of density between clusters,and assign sample points to the corresponding clusters.Compared with the perfor-mance indicators of DPC,FKNN-DPC,and three other classic clustering algorithms,the NNN-DPC algorithm has a great advantage.
-
Link Prediction of Complex Network Based on Improved AdaBoost Algorithm
龚追飞, 魏传佳. 基于改进AdaBoost算法的复杂网络链路预测[J]. 计算机科学, 2021, 48(3): 158-162.
GONG Zhui-fei, WEI Chuan-jia. Link Prediction of Complex Network Based on Improved AdaBoost Algorithm[J]. Computer Science, 2021, 48(3): 158-162. - GONG Zhui-fei, WEI Chuan-jia
- Computer Science. 2021, 48 (3): 158-162. doi:10.11896/jsjkx.200600075
-
Abstract
PDF(1798KB) (
1308
)
- References | Related Articles | Metrics
-
Link prediction is an important research direction of complex networks.The accuracy of current link prediction algorithm is limited due to limited network information available.In order to improve the link prediction performance of complex network,the improved AdaBoost algorithm is used to predict the link.Firstly,according to the complex network samples,the adjacency matrix is established,and the connection relationship between network nodes is constructed.Then the AdaBoost algorithm is used for classification training,and the prediction results are obtained by weight voting.Finally,considering the imbalance of the distribution of positive and negative errors in the prediction of complex network structure,the weight readjustment factor η and its adjustment range are set [η1,η2].The weight of multiple weak classifiers in AdaBoost algorithm is dynamically adjusted according to the value to obtain accurate link prediction results.Experiments show that,compared with other common network link prediction algorithms and traditional AdaBoost algorithm,the improved AdaBoost algorithm has obvious advantages in prediction accuracy,and when there are a large number of nodes,the difference of prediction time performance between the improved AdaBoost and other algorithms is small.
-
Minimal Optimistic Concept Generation Algorithm Based on Equivalent Relations
温馨, 闫心怡, 陈泽华. 基于等价关系的最小乐观概念格生成算法[J]. 计算机科学, 2021, 48(3): 163-167.
WEN Xin, YAN Xin-yi, CHEN Ze-hua. Minimal Optimistic Concept Generation Algorithm Based on Equivalent Relations[J]. Computer Science, 2021, 48(3): 163-167. - WEN Xin, YAN Xin-yi, CHEN Ze-hua
- Computer Science. 2021, 48 (3): 163-167. doi:10.11896/jsjkx.200100046
-
Abstract
PDF(1950KB) (
1125
)
- References | Related Articles | Metrics
-
Rule extraction of decision information system is an important topic in the field of data mining.Concept lattice theory and rough set theory are both theoretical tool for data analysis.This paper explores the relationship between these two theories,and uses the equivalent relationship to define the minimal optimistic concept lattice and its structure.The minimal optimistic concept is different from the traditional classic concept,but has a lattice structure,and a rule extraction algorithm for decision table is proposed.Based on granular computing,the algorithm computes the concepts in each layer from coarse to fine granularity space,and extracts decision rules according to the relationship between minimal optimistic concepts and decision equivalence classes.In order to achieve the purpose of knowledge reduction for decision information systems,the algorithm accelerates its convergent speed by setting the termination conditions.The definition of minimal optimistic concept is broader than classical concept,and the generation algorithm is simpler.The correctness and effectiveness of the new algorithm are verified by theorem proving and case analysis.Finally,the experimental results based on different data sets demonstrate that the proposed algorithm is more effective for rule extraction in most cases than other algorithms.
-
Collaborative Filtering Recommendation Algorithm Based on Multi-context Information
郝志峰, 廖祥财, 温雯, 蔡瑞初. 基于多上下文信息的协同过滤推荐算法[J]. 计算机科学, 2021, 48(3): 168-173.
HAO Zhi-feng, LIAO Xiang-cai, WEN Wen, CAI Rui-chu. Collaborative Filtering Recommendation Algorithm Based on Multi-context Information[J]. Computer Science, 2021, 48(3): 168-173. - HAO Zhi-feng, LIAO Xiang-cai, WEN Wen, CAI Rui-chu
- Computer Science. 2021, 48 (3): 168-173. doi:10.11896/jsjkx.200700101
-
Abstract
PDF(1413KB) (
1841
)
- References | Related Articles | Metrics
-
With the development of e-commerce and the Internet,as well as the explosive growth of data information,collaborative filtering algorithm as a simple and efficient recommendation algorithm can effectively alleviate the problem of information explosion.However,the traditional collaborative filtering algorithm only uses a single rating to mine similar users,and the recommendation effect is not dominant.In order to improve the quality of personalized recommendations,how to make full use of the user (items) text,pictures,labels and other information to maximize the value of data is an urgent problem to be solved by the current recommendation system.Therefore,user-product interaction information is used as a bipartite graph,and different simila-rity networks are constructed according to the characteristics of different contexts.The design objective function is combined with matrix decomposition under the constraints of various information networks and user or item embedding can be gotten.Extensive experiments are conducted on multiple data sets,and the results show that the collaborative filtering algorithm by fusion of multiple types of information can effectively improve the accuracy of recommendations and alleviate the problem of data sparsity.
-
Technology Data Analysis Algorithm Based on Relational Graph
张寒烁, 杨冬菊. 基于关系图谱的科技数据分析算法[J]. 计算机科学, 2021, 48(3): 174-179.
ZHANG Han-shuo, YANG Dong-ju. Technology Data Analysis Algorithm Based on Relational Graph[J]. Computer Science, 2021, 48(3): 174-179. - ZHANG Han-shuo, YANG Dong-ju
- Computer Science. 2021, 48 (3): 174-179. doi:10.11896/jsjkx.191200154
-
Abstract
PDF(2137KB) (
1524
)
- References | Related Articles | Metrics
-
With the continuous growth of scientific and technological data,various science and technology departments have accumulated a large number of scientific and technological management data of scientific and technological projects.For a large amount of structured data,it is necessary to organize and analyze the distributed data,and finally provide data query and extraction ser-vices according to requirements.The analysis of relationships in relational databases is not effective.In order to improve the efficiency of analysis,relational graphs are introduced for data processing.Firstly,an entity search and localization algorithm based on word frequency is proposed,and the entities and relationships are extracted to construct the relationalgraph.Secondly,an improved FP-growth algorithm for frequent item mining of graph data is proposed in order to solve the frequent item screening problem in the graph data.Then,a data filtering process based on graph data is designed.In addition,this paper defines the scoring matrix,evaluate the screening data,and finally give an analysis opinion.The evaluation standard of data screening can be customized.Finally,combined with the constructed relational graph,the algorithm is applied in practice and encapsulated as a ser-vice.Experimentalresults show that the improved FP-growth-based frequent item mining algorithm has 10%~12% improvement over the traditional FP-growth algorithm.The accuracy of the data screening process designed in this paper reaches 97%.
-
Overview of Research on Model-free Reinforcement Learning
秦智慧, 李宁, 刘晓彤, 刘秀磊, 佟强, 刘旭红. 无模型强化学习研究综述[J]. 计算机科学, 2021, 48(3): 180-187.
QIN Zhi-hui, LI Ning, LIU Xiao-tong, LIU Xiu-lei, TONG Qiang, LIU Xu-hong. Overview of Research on Model-free Reinforcement Learning[J]. Computer Science, 2021, 48(3): 180-187. - QIN Zhi-hui, LI Ning, LIU Xiao-tong, LIU Xiu-lei, TONG Qiang, LIU Xu-hong
- Computer Science. 2021, 48 (3): 180-187. doi:10.11896/jsjkx.200700217
-
Abstract
PDF(1789KB) (
4837
)
- References | Related Articles | Metrics
-
Reinforcement Learning (RL) is a different learning paradigm from supervised learning and unsupervised learning.It focuses on the interacting process between agent and environment to maximize the accumulated reward.The commonly used RL algorithm is divided into Model-based Reinforcement Learning (MBRL) and Model-free Reinforcement Learning (MFRL).In MBRL,there is a well-designed model to fit the state transition of the environment.In most cases,it is difficult to build an accurate enough model under prior knowledge.In MFRL,parameters in the model are fine-tuned through continuous interactions with the environment.The whole process has good portability.Therefore,MFRL is widely used in various fields.This paper reviews the recent research progress of MFRL.Firstly,an overview of basic theory is given.Then,three types of classical algorithms of MFRL based on value function and strategy function are introduced.Finally,the related researches of MFRL are summarized and prospected.
-
Prediction of RFID Mobile Object Location Based on LSTM-Attention
刘嘉琛, 秦小麟, 朱润泽. 基于LSTM-Attention的RFID移动对象位置预测[J]. 计算机科学, 2021, 48(3): 188-195.
LIU Jia-chen, QIN Xiao-lin, ZHU Run-ze. Prediction of RFID Mobile Object Location Based on LSTM-Attention[J]. Computer Science, 2021, 48(3): 188-195. - LIU Jia-chen, QIN Xiao-lin, ZHU Run-ze
- Computer Science. 2021, 48 (3): 188-195. doi:10.11896/jsjkx.200600134
-
Abstract
PDF(2019KB) (
1550
)
- References | Related Articles | Metrics
-
With the continuous development of radio frequency identification (RFID) technology,due to its advantages of high accuracy and large amount of data information compared to global positioning system (GPS),the application of RFID to intelligent transportation to predict the location of moving objects attracts widespread attention.However,due to the discrete distribution of its positioning base stations,the different influences weight of different base stations on position prediction,and the long-term historical information will bring dimensional disasters and other issues,and the position prediction of mobile objects is facing severe challenges.In response to these challenges,based on the analysis of the shortcomings of existing prediction algorithms,a machine learning model combining long short-term memory (LSTM) and attention mechanism is proposed.This algorithm reduces the dimension of the input vector encoded by one-hot through the neural network,and uses the attention mechanism to explore the weighting effect of different positioning base stations on position prediction,and finally performs position prediction.Compa-rative experiment on the RFID data set provided by Nanjing Traffic Management Bureau shows that compared with the existing algorithms,the LSTM-Attention algorithm has a significant improvement in prediction accuracy.
-
Real-time Low Power Consumption Aircraft Neural Network
张英, 陶磊岩, 曹健, 王世会, 赵茜, 张兴. 实时低功耗飞行器神经网络[J]. 计算机科学, 2021, 48(3): 196-200.
ZHANG Ying, TAO Lei-yan, CAO Jian, WANG Shi-hui, ZHAO Qian, ZHANG Xing. Real-time Low Power Consumption Aircraft Neural Network[J]. Computer Science, 2021, 48(3): 196-200. - ZHANG Ying, TAO Lei-yan, CAO Jian, WANG Shi-hui, ZHAO Qian, ZHANG Xing
- Computer Science. 2021, 48 (3): 196-200. doi:10.11896/jsjkx.191200142
-
Abstract
PDF(1695KB) (
1144
)
- References | Related Articles | Metrics
-
In order to meet the information processing requirements of a large amount of heterogeneous input data in the real-time flight of aircraft,this paper proposes a neural network,including convolution core with fixed-point sliding,pooling core with compression quantization and fully connected core with compression fusion.The input of the system is heterogeneous sensor data,and the output of the system is the identification results.Convolution core can extract data features quickly by eliminating redundant data sliding window.Pooling core improves system execution efficiency by using compression quantization technology.The design meets the on-line intelligent integrationrequirements of high reliability and low power consumption.With the proposed compression quantization method,the peak accuracy is 98.54%,the compression rate is 77.8%,and the running speed increases by 40 times.
-
Inductive Learning Algorithm of Graph Node Embedding Based on KNN and Matrix Transform
贺苗苗, 郭卫斌. 基于KNN与矩阵变换的图节点嵌入归纳式学习算法[J]. 计算机科学, 2021, 48(3): 201-205.
HE Miao-miao, GUO Wei-bin. Inductive Learning Algorithm of Graph Node Embedding Based on KNN and Matrix Transform[J]. Computer Science, 2021, 48(3): 201-205. - HE Miao-miao, GUO Wei-bin
- Computer Science. 2021, 48 (3): 201-205. doi:10.11896/jsjkx.191200156
-
Abstract
PDF(1431KB) (
1338
)
- References | Related Articles | Metrics
-
Low-dimensional embedding of graph nodes is very useful in various prediction tasks,such as protein function prediction,content recommendation and so on.However,most methods cannot be naturally extended to invisible nodes.Graph Sample and Aggregate (Graph Sample and Aggregate,Grasage) algorithm can improve the speed of invisible node generation embedding,but it is easy to introduce noise data,and the representation ability of generated node embedding is not high.In this paper,an inductive learning algorithm based on KNN and matrix transformation for graph node embedding is proposed.Firstly,K neighbo-ring nodes are selected by KNN.Then aggregation information is generated by aggregation function.Finally,aggregation information and node information are calculated by matrix transformation and full connection layer,and new node embedding is obtained.In order to balance computing time and performance effectively,this paper proposes a new aggregation function,which uses maximum pooling as aggregation information output for neighbor node features,retains more neighbor node information and reduces computing cost.Experiments on two data sets of reddit and PPI show that the proposed algorithm achieves 4.995% and 10.515% improvement on micro-f1 and macro-f1,respectively.The experimental data fully show that the algorithm can greatly reduce noise data,improve the representation ability of node embedding,and quickly and effectively generate node embedding for invisible nodes and invisible graphs.
-
Prediction of Protein Subcellular Localization Based on Clustering and Feature Fusion
王艺皓, 丁洪伟, 李波, 保利勇, 张颖婕. 基于聚类与特征融合的蛋白质亚细胞定位预测[J]. 计算机科学, 2021, 48(3): 206-213.
WANG Yi-hao, DING Hong-wei, LI Bo, BAO Li-yong, ZHANG Ying-jie. Prediction of Protein Subcellular Localization Based on Clustering and Feature Fusion[J]. Computer Science, 2021, 48(3): 206-213. - WANG Yi-hao, DING Hong-wei, LI Bo, BAO Li-yong, ZHANG Ying-jie
- Computer Science. 2021, 48 (3): 206-213. doi:10.11896/jsjkx.200200081
-
Abstract
PDF(2093KB) (
1495
)
- References | Related Articles | Metrics
-
The prediction of protein subcellular location is not only an important basis for the study of protein structure and function,but also of great significance for understanding the pathogenesis of some diseases,drug design and discovery.However,how to use machine learning to accurately predict the location of protein subcellular has always been a challenging scientific problem.To solve this problem,this paper proposes a protein subcellular localization method based on clustering and feature fusion.Firstly,autocorrelation coefficient method and entropy density method are introduced into the construction of protein feature expression model,and an improved PseAAC(Pseudo-amino acid composition) method is proposed on the basis of traditional PseAAC.In order to express protein sequence information better,this paper fuses autocorrelation coefficient method,entropy density method and the improved PseAAC to construct a new protein sequence representation model.Secondly,we use principal component analysis (PCA) to reduce the dimension of the fused feature vector.Thirdly,we adopt the LibD3C ensemble classifier to classify and predict protein subcellular,and the prediction accuracy is evaluated by leave-one-out cross validation on Gram-positive and Gram-negative datasets.Finally,the experimental results are compared with other existing algorithms.The results show that the new method achieves the prediction accuracy of 99.24% and 95.33% on Gram-positive and Gram-negative datasets respectively,and the new method is scientific and effective.
-
Label Propagation Algorithm Based on Weighted Samples and Consensus-rate
储杰, 张正军, 汤鑫瑶, 黄振生. 基于加权样本和共识率的标记传播算法[J]. 计算机科学, 2021, 48(3): 214-219.
CHU Jie, ZHANG Zheng-jun, TANG Xin-yao, HUANG Zhen-sheng. Label Propagation Algorithm Based on Weighted Samples and Consensus-rate[J]. Computer Science, 2021, 48(3): 214-219. - CHU Jie, ZHANG Zheng-jun, TANG Xin-yao, HUANG Zhen-sheng
- Computer Science. 2021, 48 (3): 214-219. doi:10.11896/jsjkx.191200103
-
Abstract
PDF(1696KB) (
1091
)
- References | Related Articles | Metrics
-
Label Propagation is one of the most widely used semi-supervised classification methods.Consensus rate-based label propagation(CRLP) algorithmconstructs the graph by summarizing multiple clustering solutions to incorporate various properties of the data.Like most graph-based semi-supervised classification method,CRLP focuses on optimizing the graph to improve the performance.In fact,samples are not always evenly distributed.The importance of different samples in the algorithm is diffe-rent.CRLP algorithm is easily affected by the numbers of clustering and the clustering methods,and it is not adaptable to low-dimensional data.To deal with these problems,a label propagation algorithm based on weighted samples and consensus-rate (WSCRLP) is proposed.WSCRLP firstly clusters the dataset multiple times to explore the structure of sample and combines the consensus-rate and the local information of the sample to construct a graph.Secondly,different weights are assigned to labeled samples with different distributions.Finally,semi-supervised classification is performed based on constructed graph and weighted samples.Experiments on real datasets show that the WSCRLP of weighting and constructing graphs on labeled samples can significantly improve classification accuracy,and is superior to other compared methods in 84% of the experiments.Compared with CRLP,WSCRLP not only has better performance,but also is robust to input parameters.
-
Character-level Feature Extraction Method for Railway Text Classification
鲁博仁, 胡世哲, 娄铮铮, 叶阳东. 面向铁路文本分类的字符级特征提取方法[J]. 计算机科学, 2021, 48(3): 220-226.
LU Bo-ren, HU Shi-zhe, LOU Zheng-zheng, YE Yang-dong. Character-level Feature Extraction Method for Railway Text Classification[J]. Computer Science, 2021, 48(3): 220-226. - LU Bo-ren, HU Shi-zhe, LOU Zheng-zheng, YE Yang-dong
- Computer Science. 2021, 48 (3): 220-226. doi:10.11896/jsjkx.200200061
-
Abstract
PDF(2659KB) (
1632
)
- References | Related Articles | Metrics
-
Railway text classification is of great practical significance to the development of China’s railway industry.Existing Chinese text feature extraction methods rely on word segmentation in advance.However,due to the low accuracy of word segmentation for railway text data,the feature extraction of railway text has limitations such as inadequate semantic understanding and incomplete feature acquisition.In view of the above problems,a character-level feature extraction method,CLW2V (Character Le-vel-Word2Vec),is proposed,which effectively solves the problem caused by the rich and high complexity of professional vocabulary in railway texts.Compared with the TF-IDF and Word2Vec methods based on lexical features,the CLW2V method based on character features extracts more refined text features,which solves the problem of poor feature extraction effect caused by the dependence on presegmentation in traditional methods.Experimental verification is carried out on the data set of railway safety supervision and licensing,which shows that the CLW2V feature extraction method for railway text classification is superior to the traditional TF-IDF and Word2Vec methods that rely on word segmentation.
-
Process Supervision Based Sequence Multi-task Method for Legal Judgement Prediction
张春云, 曲浩, 崔超然, 孙皓亮, 尹义龙. 基于过程监督的序列多任务法律判决预测方法[J]. 计算机科学, 2021, 48(3): 227-232.
ZHANG Chun-yun, QU Hao, CUI Chao-ran, SUN Hao-liang, YIN Yi-long. Process Supervision Based Sequence Multi-task Method for Legal Judgement Prediction[J]. Computer Science, 2021, 48(3): 227-232. - ZHANG Chun-yun, QU Hao, CUI Chao-ran, SUN Hao-liang, YIN Yi-long
- Computer Science. 2021, 48 (3): 227-232. doi:10.11896/jsjkx.200700056
-
Abstract
PDF(1740KB) (
1851
)
- References | Related Articles | Metrics
-
Legal judgment prediction is an application of artificial intelligence technology in legal field.Hence,the research on the legal judgment prediction method has important theoretical value and practical significance for the realization of intelligent justice.Traditional legal judgment prediction methods only make single task prediction or just use multi-task prediction based on parameter sharing,without considering the sequence dependence among subtasks,so the prediction performance is difficult to be further improved.This paper proposes a process supervision based sequence multi-task framework (PS-SMTL) by encoding sequence dependency of subtasks in legal judgement.It is an end to end legal judgement prediction method without any external features.By introducing process supervision,the proposed model ensures the accuracy of the obtained dependent prior information from advance tasks.The proposed model is applied to CAIL2018 dataset and a good classification result is achieved.The average classification accuracy is 2% higher than that of the existing state-of-the-art method.
-
Chinese Named Entity Recognition Based on Contextualized Char Embeddings
张栋, 陈文亮. 基于上下文相关字向量的中文命名实体识别[J]. 计算机科学, 2021, 48(3): 233-238.
ZHANG Dong, CHEN Wen-liang. Chinese Named Entity Recognition Based on Contextualized Char Embeddings[J]. Computer Science, 2021, 48(3): 233-238. - ZHANG Dong, CHEN Wen-liang
- Computer Science. 2021, 48 (3): 233-238. doi:10.11896/jsjkx.191200074
-
Abstract
PDF(1502KB) (
1810
)
- References | Related Articles | Metrics
-
Named Entity Recognition (NER) is designed to identify and classify proper nouns in text.Training data for supervised learning are usually manually annotated,and it is difficult to obtain large-scale annotated data due to time-consuming and labor-intensive.In order to solve the problem of data sparseness caused by the lack of large-scale annotation corpus and the problem of polysemy of charembeddingin the Chinese NER task,this paper uses contextualized char embeddings which is pre-trained on large-scale unlabeled data to improve the performance of the Chinese NER model.Furthermore,to solve the problem of out-of-vocabulary words in named entity recognition,this paper proposes a Chinese NER system based on word language model.We use the contextualized char embeddings of generated by the language model as the input of the NER model to capture different mea-nings of Chinese characters in different contexts.In this paper,we conduct experiments on six Chinese NER datasets.The experimental results show that the proposed model can improve the performance and the average F1 improves by 4.95%.In addition,this paper further analyzes the experimental results and finds that the proposed model can achieve better results on OOV entities,and it has good performance for some special types of Chinese entity recognition.
-
Intelligent Optimization Technology of Production Scheduling Under Multiple Constraints
周秋艳, 肖满生, 张龙信, 张晓丽, 杨文理. 多约束条件下生产排程智能优化技术[J]. 计算机科学, 2021, 48(3): 239-245.
ZHOU Qiu-yan, XIAO Man-sheng, ZHANG Long-xin, ZHANG Xiao-li, YANG Wen-li. Intelligent Optimization Technology of Production Scheduling Under Multiple Constraints[J]. Computer Science, 2021, 48(3): 239-245. - ZHOU Qiu-yan, XIAO Man-sheng, ZHANG Long-xin, ZHANG Xiao-li, YANG Wen-li
- Computer Science. 2021, 48 (3): 239-245. doi:10.11896/jsjkx.200300105
-
Abstract
PDF(2691KB) (
2586
)
- References | Related Articles | Metrics
-
Aiming at problems that multiple process routes sharing working procedures and orders in the production process have multiple constraint conditions(duration,priority,output,etc) in the current intelligent optimization production,an intelligent optimization algorithm of production scheduling based on the “shortest waiting time” is proposed.By comprehensively considering factors such as work order priority,duration,and urgent task insertion ,a recursive algorithm is used to calculate the waiting time of order.Taking minimizing the completion time of work order and maximizing the utilization of resources as optimization objectives,a quick response mechanism of emergency work order processing under multi-constraint conditions is established.The practical application in garment processing enterprise shows that,compared with manual scheduling and other traditional algorithms,the optimized scheduling algorithm proposed in this paper shortens the production cycle,maximizes the load rate of each process,improves the production efficiency of enterprise by more than 20%,and improves the stability of the scheduling system.
-
State-of-the-art Survey on Reconfigurable Data Center Networks
张登科, 王兴伟, 何强, 曾荣飞, 易波. 可重构数据中心网络研究综述[J]. 计算机科学, 2021, 48(3): 246-258.
ZHANG Deng-ke, WANG Xing-wei, HE Qiang, ZENG Rong-fei, YI bo. State-of-the-art Survey on Reconfigurable Data Center Networks[J]. Computer Science, 2021, 48(3): 246-258. - ZHANG Deng-ke, WANG Xing-wei, HE Qiang, ZENG Rong-fei, YI bo
- Computer Science. 2021, 48 (3): 246-258. doi:10.11896/jsjkx.201100038
-
Abstract
PDF(4332KB) (
2409
)
- References | Related Articles | Metrics
-
Hyper-scale data centers have become the key infrastructure in digital society.The prosperity of user applications has caused exponential growth of east-west traffic in the Data Center Networks (DCNs),and simultaneously,the diversification of user applications has led to serious traffic skew problems.On the other hand,the growth of network equipment capacity becomes slow in the post-Moore era,with the breakdown of Dennard scaling.Reconfigurable Data Center Networks (RDCNs) emerge when data centers are facing the pressures from the surge of users and the skew traffic as well as the CMOS performance wall.Firstly,this paper presents five motivations of RDCNs.Then,two types of enabling physical technologies for RDCNs are summarized and the research status of RDCNs is elaborated in detail in terms of the three-design space,i.e.,link-level reconfiguration,layer-level reconfiguration and topology-level reconfiguration.In addition,theoretical research results of RDCNs are introduced.Finally,the future work is presented and the whole paper is concluded.
-
Survey of Cloud-edge Collaboration
陈玉平, 刘波, 林伟伟, 程慧雯. 云边协同综述[J]. 计算机科学, 2021, 48(3): 259-268.
CHEN Yu-ping, LIU Bo, LIN Wei-wei, CHENG Hui-wen. Survey of Cloud-edge Collaboration[J]. Computer Science, 2021, 48(3): 259-268. - CHEN Yu-ping, LIU Bo, LIN Wei-wei, CHENG Hui-wen
- Computer Science. 2021, 48 (3): 259-268. doi:10.11896/jsjkx.201000109
-
Abstract
PDF(1593KB) (
9322
)
- References | Related Articles | Metrics
-
In the scenarios of Internet of things,large traffic and so on,traditional cloud computing has the advantages of strong resource service ability and the disadvantages of long-distance transmission,and the rising edge computing has the advantages of low transmission delay and the disadvantage of resource limitation.Therefore,cloud-edge collaboration,which combines the advantages of cloud computing and edge computing,has attractedmuch attention.Based on the comprehensive investigation and analysis of the relevant literature on cloud edge collaboration,this paper focuses on the in-depth analysis and discussion of the implementation principles,research ideas and progress of cloud collaboration technologies,such as resource collaboration,data collaboration,intelligent collaboration,business orchestration collaboration,application management collaboration and service colla-boration.And then,it analyzes the role of various collaborative technologies in collaboration and the specific used methods,and compares the results from the aspects of delay,energy consumption and other performance indicators.Finally,the challenges and future development direction of cloud edge collaboration are pointed out.This review is expected to provide a useful reference for the research of cloud-edge collaboration.
-
Collaborative Optimization of Joint User Association and Power Control in NOMA Heterogeneous Network
程云飞, 田红心, 刘祖军. NOMA系统异构网络中联合用户关联和功率控制协同优化[J]. 计算机科学, 2021, 48(3): 269-274.
CHENG Yun-fei, TIAN Hong-xin, LIU Zu-jun. Collaborative Optimization of Joint User Association and Power Control in NOMA Heterogeneous Network[J]. Computer Science, 2021, 48(3): 269-274. - CHENG Yun-fei, TIAN Hong-xin, LIU Zu-jun
- Computer Science. 2021, 48 (3): 269-274. doi:10.11896/jsjkx.191100213
-
Abstract
PDF(2278KB) (
1384
)
- References | Related Articles | Metrics
-
Aiming at the two-layer heterogeneous network of non-orthogonal multiple access(NOMA) system,a cooperative optimization problem of user association and power control based on utility function maximization model is proposed.In this problem,the total energy efficiency of the system is taken as a utility function,and a joint user correlation and power control algorithm is proposed under the constraint of certain QoS and maximum power limit.This algorithm first converts the original problem with parameter polynomial form of the problem.In the outer loop,it uses the dichotomy of optimal energy efficiency factor.Then in the inner loop,respectively,it uses distributed user correlation algorithm and power control algorithm to get the best user incidence matrix and optimal transmission power.Finally,it realizes the system energy efficiency maximization.Simulation results show that the proposed algorithm performs better in energy efficiency than the single fixed power allocation scheme and fixed user association scheme.
-
Earth Station Network Planning Method for Heterogeneous Communication Satellites
严佳洁, 祖家琛, 胡谷雨, 邵东生, 王帅辉. 面向异构通信卫星的地球站组网规划方法[J]. 计算机科学, 2021, 48(3): 275-280.
YAN Jia-jie, ZU Jia-chen, HU Gu-yu, SHAO Dong-sheng, WANG Shuai-hui. Earth Station Network Planning Method for Heterogeneous Communication Satellites[J]. Computer Science, 2021, 48(3): 275-280. - YAN Jia-jie, ZU Jia-chen, HU Gu-yu, SHAO Dong-sheng, WANG Shuai-hui
- Computer Science. 2021, 48 (3): 275-280. doi:10.11896/jsjkx.200600067
-
Abstract
PDF(2190KB) (
1811
)
- References | Related Articles | Metrics
-
After years of construction and development,the satellite communication industry has formed a communication system in which multiple series of satellites coexist,support and complement each other.However,how to efficiently utilize heteroge-neous satellite communication resources has become a practical problem.Therefore,according to the intercommunication conditions between satellite and earth station,a network model is first put forward and formulated as a nonlinear optimization problem under linear constraints.The optimization goal is to balance the load between satellite beams,and a two-stage heuristic network planning algorithm is designed.Finally,the Matlab simulator is used to verify the proposed algorithm,reasonable parameters are set according to the characteristics of the geostationary satellite network.The simulation results show that the proposed method is superior to the enumerative search and genetic-based algorithms in load balance,and it can build networks for large-scale channel units in a short time.
-
Resource Allocation and Offloading Decision of Edge Computing for Reducing Core Network Congestion
李振江, 张幸林. 减少核心网拥塞的边缘计算资源分配和卸载决策[J]. 计算机科学, 2021, 48(3): 281-288.
LI Zhen-jiang, ZHANG Xing-lin. Resource Allocation and Offloading Decision of Edge Computing for Reducing Core Network Congestion[J]. Computer Science, 2021, 48(3): 281-288. - LI Zhen-jiang, ZHANG Xing-lin
- Computer Science. 2021, 48 (3): 281-288. doi:10.11896/jsjkx.200700025
-
Abstract
PDF(2785KB) (
1660
)
- References | Related Articles | Metrics
-
With the development of mobile Internet and IoT,more and more intelligent end devices are put into use,and a large number of computation-intensive and time-sensitive applications are widely used,such as AR/VR,smart home,and Internet of vehicles.Thus,the traffic in the network is surging,which gradually increases the pressure of the core network,and it is more and more difficult to control the network delay.At this time,the cloud-edge collaborative computing paradigm is proposed as a solution.To solve the problem of core network traffic control between the cloud and edges,this paper proposes a resource allocation and offloading decision algorithm to reduce the traffic of cloud-edge communication.First,this paper uses the designed resource allocation algorithm based on the divided time slot to improve the processed traffic of edges.Then,it uses the genetic algorithm to search the optimal offloading decision.Experimental results show that compared with the baseline schemes,the proposed algorithm can better improve the resource utilization rate of edges,and reduces the cloud-side communication traffic,and thus redu-cing the potential congestion of the core network.
-
Delivery Probability Based Routing Algorithm for Vehicular Social Network
张皓晨, 蔡英, 夏红科. 车载社交网中基于传递概率的路由算法[J]. 计算机科学, 2021, 48(3): 289-294.
ZHANG Hao-chen, CAI Ying, XIA Hong-ke. Delivery Probability Based Routing Algorithm for Vehicular Social Network[J]. Computer Science, 2021, 48(3): 289-294. - ZHANG Hao-chen, CAI Ying, XIA Hong-ke
- Computer Science. 2021, 48 (3): 289-294. doi:10.11896/jsjkx.200200097
-
Abstract
PDF(2385KB) (
1102
)
- References | Related Articles | Metrics
-
In a Vehicular Social Network(VSN),due to the rapid and random mobility of vehicles,the network topology changes constantly and the communication link breaks frequently.And thus,the loss rate and the transmission delay are high during message transmission.In order to solve these problems,a delivery probability-based routing algorithm named ProSim is proposed.Opportunistic encounters between nodes are used for message transmission,and the social relationship between vehicles is used to design the routing algorithm.Social relationships used in this paper include the encounter probability and the social similarity between vehicles.These social relationships are quantified and used to calculate the delivery probability.By using real road data for simulation,it proves that ProSim can effectively improve the delivery ratio under the premise of controlling overhead and delay,compared with 3 classic routing algorithms including Direct Delivery,Epidemic and PRoPHET.
-
Survey on Software Defined Networks Security
董仕. 软件定义网络安全问题研究综述[J]. 计算机科学, 2021, 48(3): 295-306.
DONG Shi. Survey on Software Defined Networks Security[J]. Computer Science, 2021, 48(3): 295-306. - DONG Shi
- Computer Science. 2021, 48 (3): 295-306. doi:10.11896/jsjkx.200300119
-
Abstract
PDF(1944KB) (
2465
)
- References | Related Articles | Metrics
-
Software-defined networks(SDN) is a new network architecture,which enables separate network control plane from data planes through OpenFlow technology,thus the network traffic can be flexible controlled.SDN has become a hot topic in the next generation of Internet.With the development and wide application of SDN,its security problem has become an important research topic and some achievements have been made by the domestic and foreign scholars in recent years.Based on three-layer architecture of SDN,the security problems and solutions of each layer are summarized.Firstly,the definition and three frameworks of SDN are presented;then security issues and corresponding solutions are outlined under the data layer,the control layer and application layer;in next,the security of similarities and differences between traditional network and SDN are discussed;and finally,the research challenges in future are prposed.
-
Practical Bi-deniable Encryption Scheme Based on MLWE
郑嘉彤, 吴文渊. 基于MLWE的双向可否认加密方案[J]. 计算机科学, 2021, 48(3): 307-312.
ZHENG Jia-tong, WU Wen-yuan. Practical Bi-deniable Encryption Scheme Based on MLWE[J]. Computer Science, 2021, 48(3): 307-312. - ZHENG Jia-tong, WU Wen-yuan
- Computer Science. 2021, 48 (3): 307-312. doi:10.11896/jsjkx.200100024
-
Abstract
PDF(1415KB) (
1609
)
- References | Related Articles | Metrics
-
The traditional encryption scheme does not take into account the situation in which the adversary eavesdrops on the ciphertext to force the sender or receiver to hand over the public key,random number,plaintext,or secret key used in the encryption.Therefore,the concept of deniable encryption was proposed in 1997 to solve the information leakage caused by the coercion problem.At present,only several complete deniable encryption schemes have been proposed and implemented.However,the schemes are not practical due to the problems of low encryption efficiency and high expansion rate.By constructing a “translucent set”,a practical bi-deniable anti-quantum encryption scheme is proposed in this paper.The scheme uses the difficult problem of Module Learning With Errors (MLWE) based on polynomial ring to construct two ciphertext distributions that adversaries can’tdistinguish.The indistinguishability of two ciphertext distributions is verified by chi-square statistical experiments.The schemes’ security can be reduced to the Shortest Independent Vectors Problem (SIVP).Meanwhile,the correctness,security,deniable,expansion rate and complexity of the scheme are theoretically analyzed.And the experimental results obtained through C++are consistent with the theoretical analysis.Experimental results show that the bit error rate is about 1×10<sup>-23,the ciphertext expansion rate 5.0,and the encryption efficiency is about 670 KB/s.Therefore,it has practical application prospects in many scena-rios,such as electronic election and electronic bidding.
-
Intervention Algorithm for Distorted Information in Online Social Networks Based on Stackelberg Game
袁得嵛, 陈世聪, 高见, 王小娟. 基于斯塔克尔伯格博弈的在线社交网络扭曲信息干预算法[J]. 计算机科学, 2021, 48(3): 313-319.
YUAN De-yu, CHEN Shi-cong, GAO Jian, WANG Xiao-juan. Intervention Algorithm for Distorted Information in Online Social Networks Based on Stackelberg Game[J]. Computer Science, 2021, 48(3): 313-319. - YUAN De-yu, CHEN Shi-cong, GAO Jian, WANG Xiao-juan
- Computer Science. 2021, 48 (3): 313-319. doi:10.11896/jsjkx.200400079
-
Abstract
PDF(1901KB) (
1506
)
- References | Related Articles | Metrics
-
During the 2019-nCoV epidemic,social media spread news around the world at an unprecedented rate.Distorted information is hidden in massive social data,which presents unprecedented challenges to national security and social stability.Most of the current intervention strategies are based on the control of key nodes and key links,that is,deleting tweets and blocking accounts,which are often ineffective and prone to side effects.Based on the definition and analysis of distorted information,this paper breaks the limitation of traditional thinking and disturbs the evolution of distorted information by publishing clarifications during the spread of distorted information.With the help of Stackelberg game theory,more users are encouraged to participate in the information hedging process by setting up rewards,thereby hindering the explosive effect of distorted information.Based on the established Stackelberg game,the existence and uniqueness of the equilibrium solution are analyzed,and the closed equilibrium solution and information intervention algorithm is proposed.Simulation experiments in the actual network show that the proposed algorithm reduces the spread of distorted information by up to 41% and 9% compared to the traditional immune strategy based on network structure and other intervention algorithms based on game theory,thus can effectively suppress the spread of distor-ted information.
-
Enhanced Binary Vulnerability Mining Based on Constraint Derivation
郑建云, 庞建民, 周鑫, 王军. 基于约束推导式的增强型二进制漏洞挖掘[J]. 计算机科学, 2021, 48(3): 320-326.
ZHENG Jian-yun, PANG Jian-min, ZHOU Xin, WANG Jun. Enhanced Binary Vulnerability Mining Based on Constraint Derivation[J]. Computer Science, 2021, 48(3): 320-326. - ZHENG Jian-yun, PANG Jian-min, ZHOU Xin, WANG Jun
- Computer Science. 2021, 48 (3): 320-326. doi:10.11896/jsjkx.200700047
-
Abstract
PDF(2672KB) (
1402
)
- References | Related Articles | Metrics
-
In recent years,using software similarity methods to mine the homologous vulnerabilities has been proved to be effective,but the existing methods still have some shortcomings in accuracy.Based on the existing software similarity methods,this paper proposes an enhanced similarity method based on constraint derivation.This method uses code normalizationand standardization to reduce the compilation noise,so that the decompiled code representations of homologous programs tend to be the same under different compilation conditions.By using the backward slicing technique,it extracts the constraint derivation of vulnerability function and vulnerability patch function.By comparing the similarity of two constraint derivations,the patch function that is easily misjudged as vulnerability function is filtered out,so as to reduce false positives of vulnerability miningresults.We implement a prototype called VulFind.Experimental results show that VulFind caneffectivelyimprove the accuracy of software similarity analysis and vulnerability mining results.
-
Intrusion Detection Method Based on Borderline-SMOTE and Double Attention
刘全明, 李尹楠, 郭婷, 李岩纬. 基于Borderline-SMOTE和双Attention的入侵检测方法[J]. 计算机科学, 2021, 48(3): 327-332.
LIU Quan-ming, LI Yin-nan, GUO Ting, LI Yan-wei. Intrusion Detection Method Based on Borderline-SMOTE and Double Attention[J]. Computer Science, 2021, 48(3): 327-332. - LIU Quan-ming, LI Yin-nan, GUO Ting, LI Yan-wei
- Computer Science. 2021, 48 (3): 327-332. doi:10.11896/jsjkx.200600025
-
Abstract
PDF(1927KB) (
1267
)
- References | Related Articles | Metrics
-
With the development of Internet,the network environment is becoming more complex,and the resulting network security problems continue to emerge,so the protection of network security becomes an important research topic.Aiming at the problems of unbalanced traffic data collected in real network environment and inaccurate feature representation extracted by traditional machine learning methods,this paper proposes an intrusion detection method based on Borderline-SMOTE and dual attention.Firstly,this method performs Borderline-SMOTE oversampling on the intrusion data to solve the problem of data imbalance,and uses the advantages of convolutional networks for image feature extraction to convert 1D flow data into grayscale images.Then it updates the low-dimensional features from the channel dimension and the spatial dimension to obtain a more accurate feature representation respectively.Finally,it uses the Softmax classifier to classify and predict traffic data.The simulation experiments of the proposed method have been verified on the NSL-KDD data set,and the accuracy reaches 99.24%.Compared with other commonly used methods,it has a higher accuracy.